
Wenn du dich mit Data Analytics oder Business Intelligence (BI) beschäftigst, kennst du diese Situation vermutlich: Es gibt moderne BI-Tools, zahlreiche Dashboards und eine wachsende Menge an Daten – und trotzdem werden Zahlen hinterfragt oder Reports kaum genutzt. Entscheidungen werden dann doch wieder im Meeting diskutiert, statt auf Basis klarer Analysen getroffen zu werden. In vielen Fällen liegt das Problem nicht an fehlenden Funktionen oder mangelndem Know-how, sondern an der Qualität der Daten. Datenqualität ist das Fundament jeder Analyse – und gleichzeitig einer der am häufigsten unterschätzten Erfolgsfaktoren in Data Analytics- & BI-Projekten.
In diesem Artikel erfährst du, warum Datenqualität entscheidend für den Erfolg von Data Analytics- und BI-Lösungen ist, wo typische Probleme in der Praxis entstehen und wie Datenqualität entlang der gesamten Data Analytics-Kette sinnvoll gedacht und verbessert werden kann. Dabei geht es weniger um theoretische Modelle, sondern vor allem um ein praxisnahes Verständnis und konkrete Ansatzpunkte, um mehr Vertrauen in Daten und Analysen zu gewinnen.
Inhaltsverzeichnis
- Warum verlässliche Daten über den Erfolg von Data Analytics- & BI-Lösungen entscheiden
- Was Datenqualität eigentlich bedeutet
- Woran man im Alltag erkennt, ob Daten verlässlich sind
- Wo Probleme in der Praxis ihren Ursprung haben
- Datenqualität entlang der gesamten Data Analytics-& BI-Kette betrachten
- Wie Qualität messbar und steuerbar wird
- Datenqualität nachhaltig verbessern
- Fazit: Gute Daten als Voraussetzung für echte datengetriebene Entscheidungen
Warum verlässliche Daten über den Erfolg von Data Analytics- & BI-Lösungen entscheiden
Data Analytics- und BI-Lösungen liefern nur dann echten Mehrwert, wenn die zugrunde liegenden Daten verlässlich sind. Ist dies nicht der Fall, entstehen fehlerhafte Kennzahlen, widersprüchliche Reports und ein wachsendes Misstrauen gegenüber dem gesamten Reporting. Vielleicht hast du selbst schon erlebt, dass ein Dashboard zwar optisch überzeugt, inhaltlich aber regelmäßig hinterfragt wird.
Das bekannte Prinzip „Garbage in, garbage out“ (auf Deutsch: „Müll rein, Müll raus“) beschreibt dieses Problem sehr treffend. Wenn die Datenbasis nicht stimmt, helfen auch leistungsfähige Visualisierungen oder komplexe Analysemodelle nicht weiter. Gute Datenqualität sorgt hingegen dafür, dass du dich auf Zahlen verlassen kannst, Diskussionen sich auf Inhalte konzentrieren und Data Analytics tatsächlich als Entscheidungsunterstützung genutzt wird.
Ein hierzu passendes, sehr häufig vorkommendes Beispiel aus dem Bereich Vertrieb & Controlling: Trotz moderner Cloud-BI und Self-Service-Dashboards fehlt das Vertrauen in die Zahlen. Im Management-Meeting zeigt das Vertriebsdashboard einen rückläufigen Umsatz, während das Controlling-Reporting eine stabile Entwicklung ausweist. Nach kurzer Diskussion wird klar: unterschiedliche KPI-Definitionen, verschiedene Stichtage und uneinheitliche Datenstände führen zu mangelnder Datenqualität. Das Ergebnis: Das Dashboard wird infrage gestellt – und Entscheidungen werden vertagt.
Interessant ist auch, dass Zahlen selbst dann hinterfragt werden, wenn technisch keine widersprüchlichen Reports existieren. Gerade dann, wenn Analysen ein kritisches Licht auf bestimmte Bereiche oder Ergebnisse werfen, entstehen Zweifel – unabhängig von der tatsächlichen Datenqualität. Welche Rolle hier Kultur, Transparenz und der Umgang mit Fehlern spielen, ist ein Thema für sich.
Was Datenqualität eigentlich bedeutet
Nach solchen Situationen stellt sich oft die Frage, was mit „Datenqualität“ eigentlich konkret gemeint ist. Denn Datenqualität ist kein abstrakter IT-Begriff, sondern beschreibt Eigenschaften von Daten, die darüber entscheiden, ob Analysen verlässlich sind und als Entscheidungsgrundlage taugen.
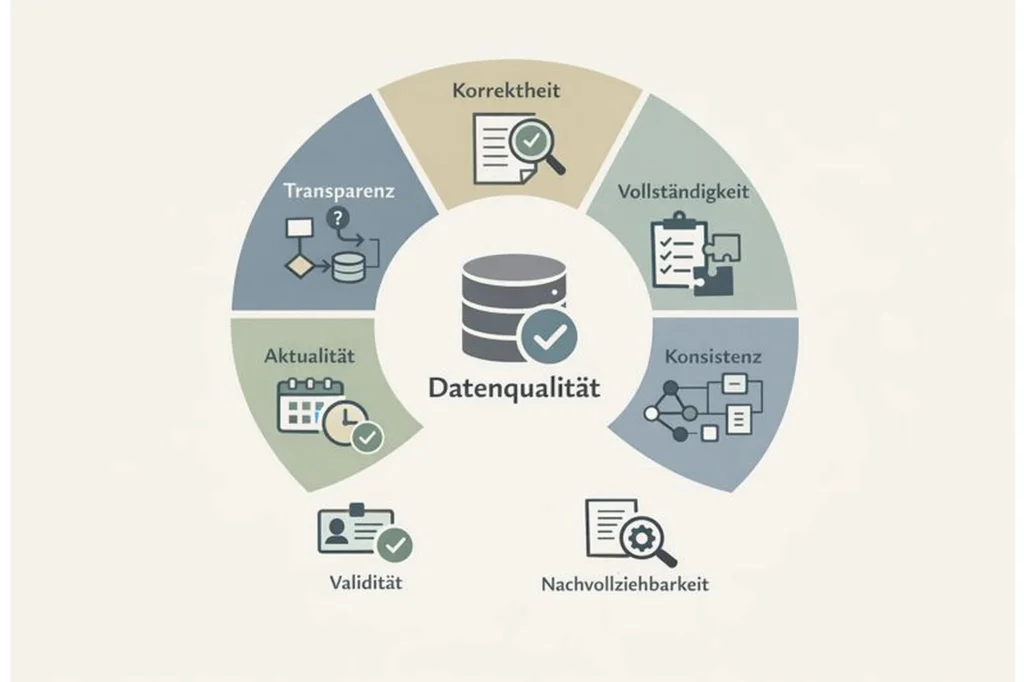
Konkret umfasst Datenqualität mehrere eng miteinander verbundene Aspekte. Zunächst geht es um die Korrektheit der Daten: Stimmen die Werte fachlich und rechnerisch? Ebenso wichtig ist die Vollständigkeit – also die Frage, ob alle relevanten Informationen vorhanden sind oder ob Daten fehlen, die Analysen verzerren.
Darüber hinaus spielt die Konsistenz eine zentrale Rolle. Kennzahlen und Logiken sollten über verschiedene Systeme, Reports und Zeiträume hinweg dieselbe Bedeutung haben. Eng damit verbunden ist die Aktualität der Daten: Analysen sind nur dann hilfreich, wenn die zugrunde liegenden Daten rechtzeitig verfügbar sind und den erwarteten Datenstand widerspiegeln.
Weitere wichtige Aspekte sind die Eindeutigkeit und Validität. Daten sollten keine Dubletten enthalten und klar zuordenbar sein. Gleichzeitig müssen sie definierten fachlichen und technischen Regeln entsprechen – etwa gültigen Wertebereichen oder konsistenten Statuslogiken.
Nicht zuletzt ist die Nachvollziehbarkeit entscheidend. Anwender müssen verstehen können, woher Daten stammen, wie sie entstehen und wie Kennzahlen berechnet werden. Fehlt diese Transparenz, entsteht schnell Unsicherheit – selbst dann, wenn die Zahlen auf den ersten Blick korrekt erscheinen.
Zusammengefasst beschreibt Datenqualität also die fachliche Verlässlichkeit, Konsistenz und Transparenz von Daten – immer mit Blick auf den jeweiligen Verwendungszweck.
Woran man im Alltag erkennt, ob Daten verlässlich sind
Wie sich diese Aspekte auswirken, zeigt sich nicht in Definitionen, sondern ganz konkret im täglichen Umgang mit Reports und Analysen. Datenqualität wird spürbar, wenn Auswertungen vollständig sind, Kennzahlen über verschiedene Berichte hinweg konsistent erscheinen und Analysen als verlässlich wahrgenommen werden.
Dabei ist Datenqualität immer vom jeweiligen Kontext abhängig. Für ein monatliches Management-Reporting gelten andere Anforderungen als für operative Steuerung oder automatisierte Forecasts. Entscheidend ist weniger absolute Perfektion als vielmehr die Frage, ob die Daten für den jeweiligen Anwendungsfall geeignet, verlässlich und zweckmäßig sind.
Vertrauen in Analysen entsteht nicht allein durch saubere Daten. Wie weiter oben bereits erwähnt spielt auch der Umgang mit Transparenz und kritischen Ergebnissen eine zentrale Rolle. Selbst korrekte Zahlen stoßen auf Skepsis, wenn sie als Bewertung von Personen oder Abteilungen wahrgenommen werden.
Wo Probleme in der Praxis ihren Ursprung haben
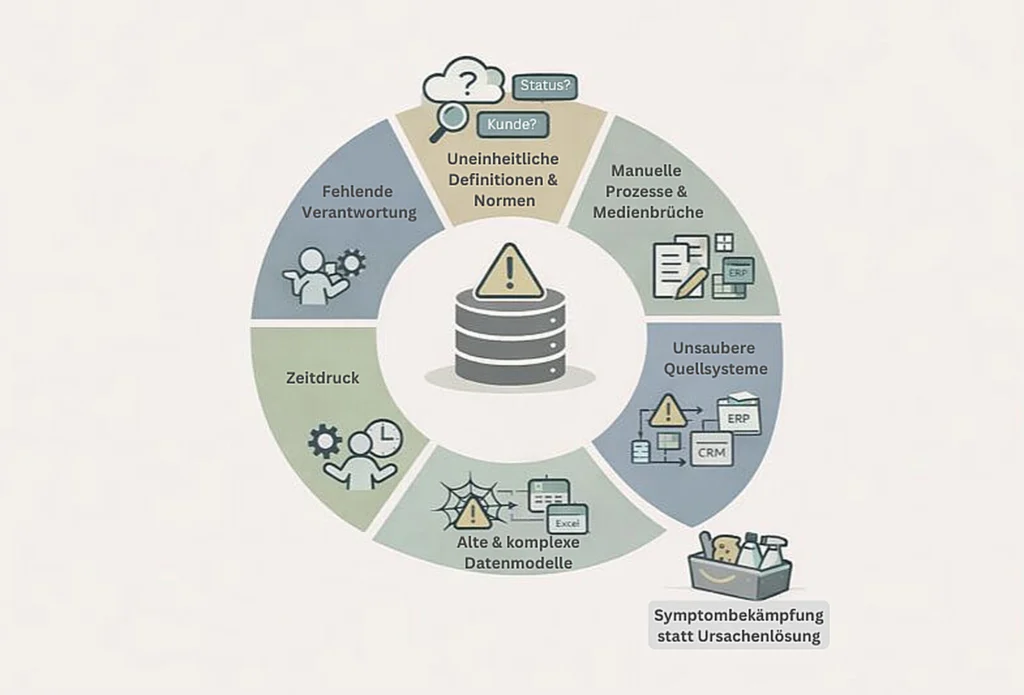
In der Praxis entstehen Probleme mit der Datenqualität selten an einer einzelnen Stelle.
1. Häufig sind sie das Ergebnis komplexer, historisch gewachsener Systemlandschaften. Wenn unterschiedliche Quellsysteme wie ERP, CRM, Excel-Auswertungen oder manuelle Erfassungen zusammengeführt werden, treffen verschiedene Datenlogiken, Strukturen und Qualitätsniveaus aufeinander. Inkonsistenzen, Dubletten oder fehlende Informationen sind dann oft die Folge.
2. Auch auf die Gefahr hin, mich zu wiederholen: ein zentraler Auslöser sind fehlende oder unklare Datennormen und Definitionen. Begriffe, Statuswerte oder fachliche Attribute sind nicht eindeutig geregelt oder werden in verschiedenen Systemen unterschiedlich interpretiert.
Ein typisches Praxisbeispiel: Bei einem Kunden war im Kundenverwaltungssystem ein zentrales Datenfeld, das eigentlich eindeutige Auswahlmöglichkeiten haben sollte, als Freitextfeld umgesetzt. Was zunächst flexibel erschien, führte in der Praxis zu uneinheitlichen Eingaben, Interpretationsspielräumen und zusätzlichem Abstimmungsaufwand – mit negativen Auswirkungen sowohl auf Prozesse (sie werden langsamer, fehleranfälliger und stärker von manuellem Wissen abhängig) als auch auf spätere Auswertungen.
Unterschiedliche Schreibweisen oder Formate, uneinheitliche Inhalte und fehlende Validierungen führen dazu, dass Informationen nicht zuverlässig verarbeitet oder geprüft werden können. Mitarbeitende müssen Inhalte interpretieren, Rückfragen stellen oder zusätzliche Hilfskonstrukte nutzen. Automatisierungen sind kaum möglich, Prozesse nicht sauber steuerbar – und auch im Reporting lässt sich das Feld nur mit hohem Aufwand sinnvoll auswerten. Ein Einfluss auf das direkte Tagesgeschäft sollte also immer als Argument für eine gute Datenqualität genutzt werden.
3. Hinzu kommen historisch gewachsene Datenmodelle, die über Jahre hinweg erweitert und angepasst wurden. Neue Anforderungen werden ergänzt, ohne bestehende Logiken konsequent zu hinterfragen. Das führt dazu, dass Daten zwar technisch verfügbar sind, fachlich jedoch nicht mehr konsistent zueinander passen.
4. Auch Medienbrüche und manuelle Prozesse tragen erheblich zu Datenqualitätsproblemen bei. Excel-Zwischenlösungen, manuelle Korrekturen oder das händische Zusammenführen von Daten erhöhen nicht nur den Aufwand, sondern auch das Risiko von Fehlern und Intransparenz.
5. Ein weiterer Faktor sind fehlende Verantwortlichkeiten. Wenn nicht klar geregelt ist, wer für Daten, Definitionen und Qualität zuständig ist, fühlt sich oft niemand verantwortlich. Datenprobleme werden dann zwar wahrgenommen, aber nicht nachhaltig behoben.
6. Nicht zuletzt spielt Zeitdruck in Data Analytics- & BI-Projekten eine Rolle. Der Fokus liegt häufig darauf, möglichst schnell erste Dashboards bereitzustellen. Aspekte der Datenqualität werden dabei bewusst oder unbewusst zurückgestellt – mit der Folge, dass sich Probleme später im laufenden Betrieb bemerkbar machen.
Datenqualität entlang der gesamten Data Analytics-& BI-Kette betrachten
Ein häufiger Fehler besteht darin, Datenqualität erst dann zu thematisieren, wenn Probleme im Dashboard sichtbar werden. Zu diesem Zeitpunkt ist der Aufwand zur Korrektur meist hoch. Nachhaltiger ist es, Datenqualität entlang der gesamten Data Analytics-Wertschöpfungskette zu betrachten – von der Datenerfassung über Transformationen bis hin zum Reporting.
Je früher du Qualitätsprobleme erkennst, desto einfacher lassen sie sich beheben. Transformationsprozesse und Datenmodelle bieten dir zahlreiche Möglichkeiten, Daten zu standardisieren, zu prüfen und konsistent aufzubereiten. Werden Fehler hingegen erst im Reporting entdeckt, bleibt oft nur die manuelle Korrektur – mit entsprechendem Zeitaufwand und eingeschränkter Skalierbarkeit.
Wie Qualität messbar und steuerbar wird
Umso wichtiger ist es, Datenqualität nicht nur zu diskutieren, sondern auch systematisch zu steuern. In vielen Unternehmen wird zwar über schlechte Daten gesprochen, jedoch nur selten konkret gemessen, wie gut oder schlecht die Daten tatsächlich sind. Dabei lässt sich Datenqualität gut quantifizieren, etwa durch regelbasierte Prüfungen, Plausibilitätschecks oder einfache Kennzahlen.
Ein besonders wirkungsvoller Ansatz besteht darin, Datenqualität selbst sichtbar zu machen, beispielsweise über ein internes Datenqualitäts-Dashboard. So entsteht Transparenz, und Datenqualität wird von einem diffusen Problem zu einer steuerbaren Größe. Gleichzeitig schafft diese Sichtbarkeit eine gemeinsame Diskussionsgrundlage und unterstützt eine kontinuierliche Verbesserung.
Datenqualität nachhaltig verbessern
Die Verbesserung der Datenqualität ist kein einmaliges Projekt, sondern ein kontinuierlicher Prozess. Einzelne Bereinigungsaktionen können kurzfristig helfen, adressieren jedoch selten die eigentlichen Ursachen. Nachhaltige Verbesserungen entstehen, wenn Datenqualität systematisch in Data Analytics- & BI-Prozesse integriert wird.
Zentrale Elemente sind klare Definitionen von Daten und Kennzahlen, möglichst automatisierte Prüfungen während der Datenverarbeitung sowie die Reduktion manueller Eingriffe. Ebenso wichtig ist es, Fehler nicht stillschweigend zu korrigieren, sondern ihre Ursachen sichtbar zu machen. Auf diese Weise entsteht schrittweise eine stabile und verlässliche Datenbasis.
Dabei ist ein pragmatischer Ansatz entscheidend: Ziel ist nicht perfekte Datenqualität um jeden Preis, sondern eine Qualität, die Analysen zuverlässig unterstützt und fundierte Entscheidungen ermöglicht.
Fazit: Gute Daten als Voraussetzung für echte datengetriebene Entscheidungen
Der erfolgreiche Einsatz von Data Analytics und Business Intelligence steht und fällt mit der Qualität der zugrunde liegenden Daten. Sie entscheidet darüber, ob Zahlen Vertrauen genießen, Reports genutzt werden und Data Analytics & BI tatsächlich Mehrwert liefert.
Datenqualität ist keine einmalige Aufgabe, sondern ein dauerhafter Bestandteil datengetriebener Arbeit. Unternehmen und Teams, die sie konsequent adressieren, schaffen nicht nur bessere Dashboards, sondern legen den Grundstein für nachhaltige, datenbasierte Entscheidungen. Gute Daten entstehen nicht zufällig – sie sind das Ergebnis bewusster Entscheidungen und konsequenter Umsetzung.
Bildnachweis: Foto von Towfiqu barbhuiya auf Unsplash